The Gemma 4 model family represents a strategic shift in open-weight AI, moving away from uniform scaling toward a multi-tier ecosystem of specialized architectures. This generation introduces Per-Layer Embeddings (PLE) for ultra-efficient edge performance and Mixture-of-Experts (MoE) for high-throughput server-side reasoning. For the enterprise architect, this taxonomy provides the flexibility to align model selection with specific hardware constraints and latency requirements, ensuring that AI deployment is no longer limited by a “one-size-fits-all” approach.
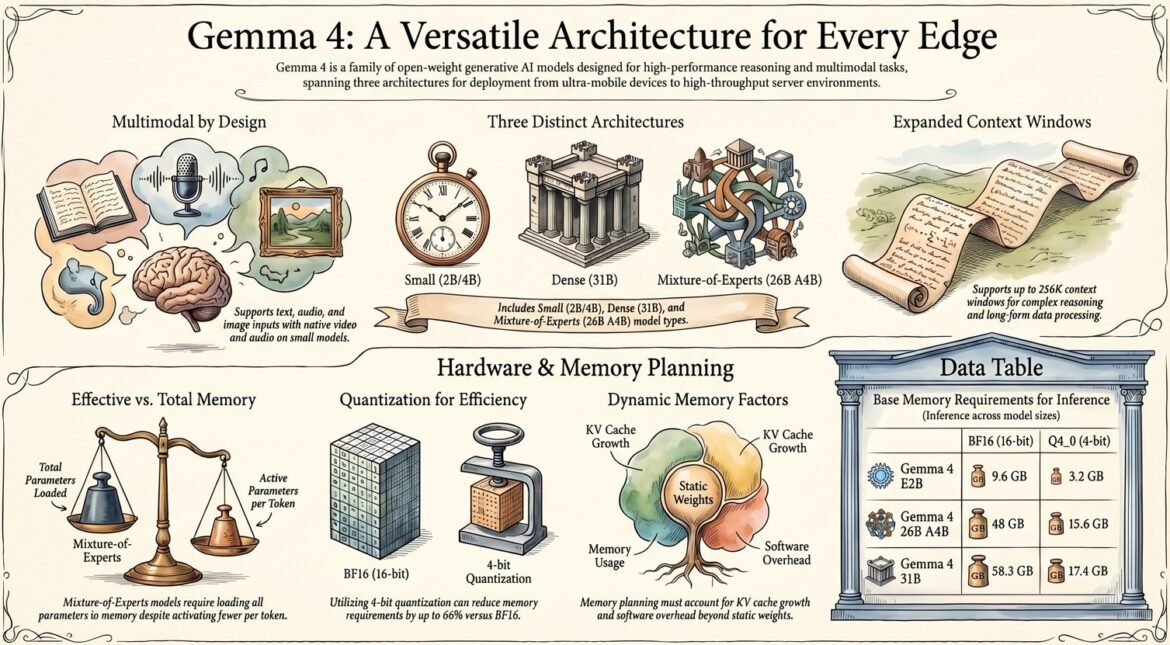
Model Variant
Architecture Type
Effective Parameter Count
Primary Deployment Target
Gemma 4 E2B
Small / PLE
2 Billion (Effective)
Mobile, Edge, & Browser (Chrome/Pixel)
Gemma 4 E4B
Small / PLE
4 Billion (Effective)
High-Performance Mobile & Edge
Gemma 4 26B A4B
Mixture-of-Experts (MoE)
26B Total (4B Active)
High-Throughput Server / Advanced Reasoning
Gemma 4 31B
Dense
31 Billion
Server-Grade Performance / Local Execution
The architectural differentiation between these tiers is critical for infrastructure planning. The “Small” PLE-based models (E2B and E4B) are engineered to maximize parameter efficiency on resource-constrained devices. In contrast, the 26B A4B MoE model is designed for throughput; by activating only 4 billion parameters per token, it provides a significant latency advantage over dense models of similar size. However, the 31B Dense model remains the gold standard for logical depth and reasoning accuracy where raw performance is the priority. This tiered strategy directly dictates the feasibility of localized versus centralized enterprise deployments, allowing for a balanced mix of edge-based privacy and server-side power.
2. Multi-Modal Intelligence and Contextual Depth
Gemma 4’s “extended multimodality” and significantly expanded context windows (up to 256K tokens) represent a fundamental shift in how enterprise data is ingested and analyzed. By consolidating text, image, audio, and video processing into a single architectural framework, Gemma 4 reduces the need for fragmented data pipelines and specialized silos. This holistic approach allows for more nuanced data synthesis and a more cohesive user experience across multimodal interfaces.
The multimodal distribution is specialized across the family:
Text and Image: Native support across all variants, including high-accuracy visual synthesis.
Native Video and Audio: Exclusive native processing features of the E2B and E4B models, enabling advanced media-handling capabilities on edge hardware without cloud dependency.
The “So What?” for enterprise architects regarding the 128K (Small) and 256K (Medium) context windows is a reduction in architectural complexity. This capacity allows for the ingestion of massive datasets—such as entire legal repositories, multi-year quarterly reports, or exhaustive technical manuals—within a single prompt. This effectively shifts the burden from complex vector database engineering (chunking, retrieval, and RAG-heavy fragmentation) back to prompt context management, simplifying the deployment stack and improving reasoning coherence.
Furthermore, image processing is enhanced through:
Variable Aspect Ratio Support: Critical for “Document AI” use cases, ensuring that wide-format charts, technical diagrams, and tables in PDFs are processed without distorting or losing data to forced cropping.
Variable Resolution Support: Dynamically adjusts to high-detail visual inputs, essential for reading dense text within complex graphical environments.
3. Agentic Foundations and Advanced Reasoning
Gemma 4 marks the evolution of the model from a passive text generator to a proactive agentic engine. This shift is facilitated by a focus on logical reasoning density and built-in support for structured interactions, transforming the model into a controller capable of navigating autonomous enterprise workflows.
Strategic foundations for this agentic behavior include:
Native System Prompt Support: Introduces built-in support for the “system role,” ensuring the model adheres strictly to persona constraints and operational boundaries. This provides more reliable and controllable outputs compared to legacy prompt engineering.
Function-Calling Support: Enables the model to interface natively with external APIs and enterprise software. This allows the AI to move beyond text to execute real-world actions across a software ecosystem.
Thinking Modes and Coding Heuristics: High performance on coding benchmarks serves as a primary heuristic for “logical reasoning density.” For architects, this indicates a model’s capacity to handle multi-step, chain-of-thought business logic. “Thinking Modes” allow the model to dedicate more computational depth to complex reasoning, though architects must account for the fact that increased “thinking” cycles result in higher latency and compute costs.
Agentic Capability Framework:
Autonomous Action: Leveraging function calling to automate procurement, scheduling, or data entry.
Structured Conversations: Utilizing system prompts for high-stakes customer-facing or legal compliance roles.
Complex Problem Solving: Applying “Thinking Modes” to navigate intricate, non-linear business logic.
4. Infrastructure Requirements and Memory Management
Enterprise-grade deployment requires moving beyond nominal parameter counts to “vRAM reality.” Memory planning must account for architectural overheads that impact the footprint required for stable inference.
Per-Layer Embeddings (PLE) Impact: In the E2B and E4B models, PLE optimizes for “latency-per-token” on edge devices by giving each decoder layer its own embedding. However, this creates a VRAM bottleneck at the embedding storage level; the static weights are significantly higher than the “effective” parameter counts suggest.
MoE Routing Overhead (26B A4B): Despite activating only 4B parameters during inference, all 26 billion parameters must be loaded into memory to support the routing mechanism. This architectural trade-off prioritizes throughput over memory efficiency.
Dynamic KV Cache: The massive context windows (128K/256K) require substantial additional VRAM beyond the base weights. Architects must scale GPU allocation based on the expected prompt length and response density.
Quantization Trade-offs: Precision (bit-count) directly impacts capability. While Q4_0 reduces operational costs (power/memory), it may degrade performance in high-complexity reasoning tasks compared to BF16.
5. Strategic Enterprise Use Case Mapping
The technical innovations within Gemma 4 enable high-ROI business solutions that were previously computationally prohibitive or architecturally complex.
Autonomous Enterprise Agents: By combining function calling with native system prompts, organizations can build agents for cross-departmental workflow automation, such as autonomous supply chain management or proactive IT service desk triage.
Complex Data Intelligence: The 256K context window allows for “long-form” intelligence, such as synthesizing a decade of legal filings or performing exhaustive audits on technical documentation repositories without losing the “thread” of the data.
On-Device Edge Intelligence: The native audio/video processing and PLE efficiency of the E2B and E4B models support localized processing for mobile actions. This is ideal for field-service applications where low latency and data privacy are paramount.
Implementation Roadmap:
Development & Tuning: Utilize Keras, PyTorch, or the Gemma library for initial prototyping and Parameter-Efficient Fine-Tuning (PEFT) methods like LoRA.
Enterprise Production: Scale via vLLM for high-throughput inference, or leverage Vertex AI, Google Kubernetes Engine (GKE), and Cloud Run for managed, resilient production environments.
Gemma 4 stands as a versatile, open-weight solution for modern enterprise AI architecture, balancing specialized edge efficiency with deep server-side reasoning.
Introduction As of early 2026, AI voice input tools have evolved from simple transcription services into a critical “new input layer” for computing. These tools prioritize speed—often cited as being […]
GuidsHub was founded with a simple yet powerful vision: to be the premier destination for discovering groundbreaking products and insightful discussions from the world of Product Hunt. We believe in the power of innovation and the importance of sharing knowledge to inspire the next generation of creators and entrepreneurs.










Post comments
This post currently has no comments.